
After AI beat them, professional Go players got better and more creative


A game of the board game Go in Japan 1876
For many decades, it seemed professional Go players had reached a hard limit on how well it is possible to play. They were not getting better. Decision quality was largely plateaued from 1950 to the mid-2010s:

Then, in May 2016, DeepMind demonstrated AlphaGo, an AI that could beat the best human Go players. This is how the humans reacted:
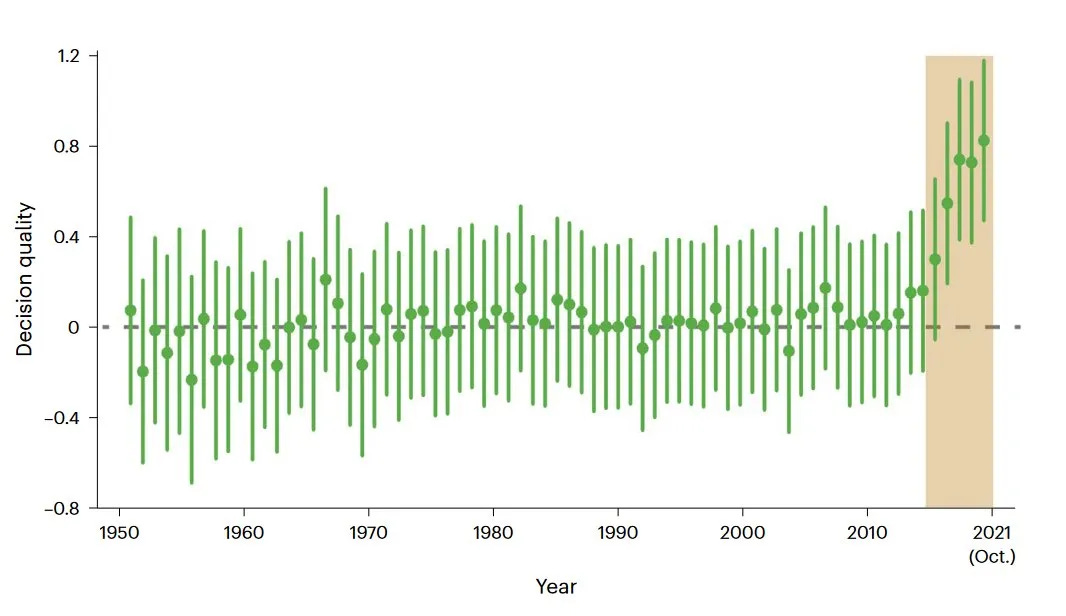
After a few years, the weakest professional players were better than the strongest players before AI. The strongest players pushed beyond what had been thought possible. EDIT: as Gwern points out, I’m misreading the graph. The graph shows the average move quality across the whole Go player population. The lines are not the population, but simply the uncertainty around the mean. So moves were getting better, but we do not know how that was distributed in the population.
Were the moves getting better because some players cheated by using the AI? No.1 They really were getting better.
And it wasn’t simply that they imitated the AI, in a mechanical way. They got more creative, too. There was an uptick in historically novel moves and sequences. Shin et al calculate about 40 percent of the improvement came from moves that could have been memorized by studying the AI. But moves that deviated from what the AI would do also improved, and these “human moves” accounted for 60 percent of the improvement.
My guess is that AlphaGo’s success forced the humans to reevaluate certain moves and abandon weak heuristics. This let them see possibilities that had been missed before.
Something is considered impossible. Then somebody does it. Soon it is standard. This is a common pattern. Until Roger Bannister ran the 4-minute mile, the best runners clustered just above 4 minutes for decades. A few months later Bannister was no longer the only runner to do a 4-minute mile. These days, high schoolers do it. The same story can be told about the French composer Pierre Boulez. His music was considered unplayable until recordings started circulating on YouTube and elsewhere. Now it is standard repertoire at concert houses.
The recent development in Go suggests that superhuman AI systems can have this effect, too. They can prove something is possible and lift people up. This doesn’t mean that AI systems will not displace humans at many tasks, and it doesn’t mean that humans can always adapt to keep up with the systems—in fact, the human Go players are not keeping up. But the flourishing of creativity and skills tells us something about what might happen at the tail end of the human skill distribution when more AI systems come online. As humans learn from AIs, they might push through blockages that have kept them stalled and reach higher.
Another interesting detail about the flourishing in Go, which is teased out in this paper by Shin, Kim, and Kim, is that the trend shift actually happened 18 months after AlphaGo. This coincides with the release of Leela Zero, an open source Go engine. Being open source Leela Zero allowed Go players to build tools, like Lizzie, that show the AI’s reasoning when picking moves. Also, by giving people direct access, it made it possible to do massive input learning2. This is likely what caused the machine-mediated unleash of human creativity.
This is not the first time this kind of machine-mediated flourishing has happened. When DeepBlue beat the chess world champion Kasparov in 1997, it was assumed this would be a blow to human chess players. It wasn’t. Chess became more popular than ever. And the games did not become machine-like and predictable. Instead, top players like Magnus Carlsen became more inventive than ever.
Our potential is greater than we realize. Even in highly competitive domains, like chess and GO, performance can be operating far below the limit of what is possible. Perhaps AI will give us a way to push through these limits in more domains.
Warmly
Henrik
Acknowledgements
Several of the points here build on comments made on a Twitter thread I made about this yesterday. Nabeel S. Qureshi (Twitter, blog) read a draft and gave useful pointers.
Notes on energy and intelligence becoming cheaper

In 2015, I amused myself by training a neural network to generate poems in the style of various poets I knew and submitted the results to a fanzine. The thing I built was a primitive language model and—though I thought it was fascinating, seeing a computer talk—it did not occur to me that it could be useful for much beyond pranks. I would never have gue…
The data in the graph which shows the improvement is from Games of Go on Disk, a project that transcribes games at professional Go tournaments. These games happen in person and have precautions against cheating. There was a recent incident in Chinese Chess when Yan Chenglong, last year's winner of the Chinese tournaments, was accused of cheating by using an anal bead that let him send information to a computer by squeezing, and receiving moves sent back as a code of vibrations—so who knows. But cheating doesn’t seem common enough to explain the trend.
It is Shin, Kim and Kim who claim Leela Zero helped because, unlike AlphaGo, it showed the reasoning behind the move, not just the move.
This is interesting in light of cognitive apprenticeship theory which posits that the reason people have a hard time learning cognitive skills, like literacy or Go, is that our learning is adapted for imitation and apprenticeship-like situations, and this works poorly for cognitive skills which happen hidden in the head. By opening up the box, so that the thought process can be observed, like Lizzie does, you allow people to apprentice themselves to the cognition, not just the actions.
I am not sure I believe this explanation! When I look at subreddits for Go players who use Lizzie, my impression is that they don’t look at the reasoning all that much. They use it mainly to pinpoint moves where the winrate suddenly drops, so they can focus their learning on their biggest mistakes.
The true explanation why open source helped might actually be the inverse of what Shin, Kim and Kim propose. It might that the reason open source helped was that it let people do massive input learning—simply flooding themselves with data on how the AI plays—and bypassing reasoning all together. It could be that reasoning was holding people back before. Human moves tend to follow heuristics that are explainable and simplify things so people can do the computations in their heads. The AIs don’t care about these heuristics and explanations and so can play cleaner. In chess parlance, the AI is more “concrete”—reasoning based on specific variations rather than on general principles. Doing massive input training on this kind of concrete play, bypassing heuristics and explanations, might be the why of the improved decision quality.
In chess, the new batch of young grandmasters in chess got there largely by playing 10+ hours a day of online speed chess instead of the older strategies that emphasized targeting learning, deliberate practice and slower exercises. This is another example of a shift toward massive input, pushing beyond heuristics to pure pattern matching, and it was, like the shift in Go, facilitated by AI engines.
> I am not sure I believe this explanation! When I look at subreddits for Go players who use Lizzie, my impression is that they don’t look at the reasoning all that much. They use it mainly to pinpoint moves where the winrate suddenly drops, so they can focus their learning on their biggest mistakes.
I think you should discount those observations a bit. The way typical players (mostly beginners and casual players) on reddit are using AI analysis in Go will not be representative of top players. I'm mid-amateur dan and still far from the top, but closer enough to stronger players that I can perceive myself some of that from my own personal experience. If you want to get a better impression of how strong players think about AI analysis, take a look at Michael Redmond's streams (9 dan pro) where he analyzes various games of both his own, or AlphaGo's games, with mention about various AI-suggested alternatives - it's not just looking for drops and parroting moves, but rather often diving deep into variations to place it into the context of his experience with similar positions.
> It is Shin, Kim and Kim who claim Leela Zero helped because, unlike AlphaGo, it showed the reasoning behind the move, not just the move.
> The true explanation why open source helped might actually be the inverse of what Shin, Kim and Kim propose. It might that the reason open source helped was that it let people do massive input learning
I don't recall who Shin, Kim, and Kim are, but assuming they're on-the-ground-informed about how players use AI in the same kinds of ways I've observed myself, then it's possible you might be misinterpreting what they are saying in a way that makes it more opposed to your proposed "true explanation" than it really is. There's a different interpretation that is not contradictory to your hypothesis. Which is that:
* Seeing just the isolated move that a strong AI proposes in a given situation is not so useful for learning. It's extremely hard to guess what situations that move generalizes to or not - slight changes to the surroundings can easily change the best moves.
* But seeing the all the sequences of moves that a strong AI proposes including all the relevant counterfactual sequences, is more useful for learning. e.g. "The AI proposes X, but the opponent can just respond Y, that seems bad for me? But the AI doesn't have the opponent respond with Y, it concedes and trades with Z! So presumably it thinks Y is not a refutation. Let me force X-Y and analyze again from there... aaah I now I see that Y fails because such and such stone is present. Now my brain is trained with the exact stone/shape/tactic to look for that makes X possible." And a dozen other different flavors of different kinds of counterfactuals that you could ask.
The latter is only possible if you actually can scroll back and forth through variations and interrogate the bot on different sequences interactively in different situations, which is only possible with e.g. a Leela Zero, and not just a static set of AlphaGo game records. And my own experience is that it actually is a big help, so long as you are independently strong enough at the game to be capable judging enough of the answers you get back when interrogating different sequences.
If you interpret Shin, Kim and Kim's "the reasoning behind the move" as referring to seeing the full sequences and counterfactual sequences, and not as referring to the low-level mechanism of learning - then there is no conflict with your hypothesis. Seeing counterfactual sequences and refutations and interrogating the bot interactively where you were unsure can be a big help for learning at the *same time* as the mechanism of that learning could be mostly pattern recognition training through lots of data. Indeed, seeing all those sequences is part of getting that concentrated data in order to train one's pattern recognition!
> After a few years, the weakest professional players were better than the strongest players before AI. The strongest players pushed beyond what had been thought possible.
I think you are misinterpreting this graph, looking at the SSRN paper (https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3893835). They do not make any statements I see about the population distribution Elo before/after or that the improvement means that an ordinary professional could now beat Ke Jie or Lee Sedol in their prime. This graph seems to just be about the average move quality across the whole Go player population increasing a bit per move. The lines are not the population, but simply the uncertainty around the mean. (This would be like estimating the American population at an average of 5-foot-7 with a standard error of 0.1 inches, and concluding that basketball players are impossible; or that if you measure the Dutch population at 5-foot-9 +- 0.1 inch, every single Dutch person is taller than every single American person; or that after a bunch of health interventions during the 1900s, the American population mean increased by 1 inch and then all young Americans were taller than all old Americans.)